
Calibration Curves and Area Under the Curve
Understanding the mathematical intuition behind calibration curves and related metrics helps clarify their diagnostic value in evaluating model reliability. This section outlines foundational concepts using simplified examples, progressing toward their real-world interpretation in model evaluation.
Calibration Curves and Area Interpretation
Calibration curves visualize how well predicted probabilities align with actual outcomes. A perfectly calibrated model lies along the diagonal line, where predicted probability equals observed frequency.
Below are two manual examples using toy functions to illustrate the concept of area under the calibration curve, a key component of metrics like Calibration AUC.
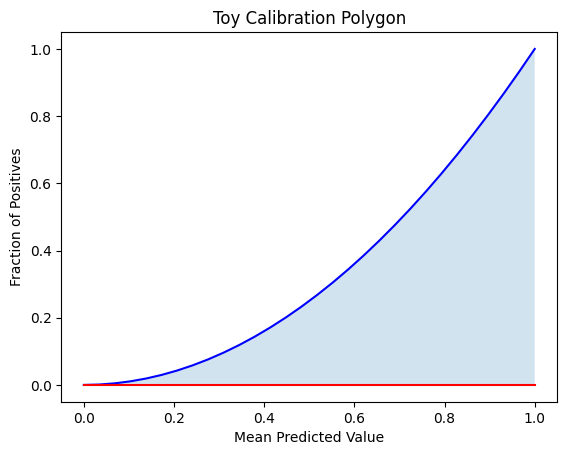
Example 1: Calibration with y = x²
This function simulates underconfident predictions, where the model consistently underestimates risk.
To compute the calibration area under this curve from ( x = 0 ) to ( x = 1 ):
Solution:
The area under the ideal calibration line (diagonal) is:
So, the polygonal calibration AUC becomes:
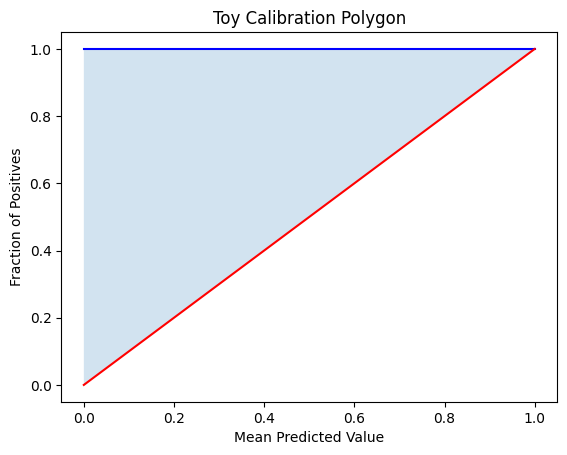
Example 2: Calibration with y = x² + 4x
This toy example models overconfident predictions, where the model consistently overshoots risk.
To calculate the area under the curve from ( x = 0 ) to ( x = 1 ), we compute the definite integral:
Solution:
We split the integral into two separate parts:
First Integral:
Second Integral:
Final Answer:
This result represents the total area under the curve \(y = x^2 + 4x\) over the interval \([0, 1]\). If comparing against the ideal calibration line \(( y = x)\), you would subtract the diagonal area \(( \frac{1}{2})\) to isolate the calibration polygon AUC.
Note
In real calibration plots, the area is bounded within [0,1] on both axes. This example is meant to illustrate the mechanics of integration over a custom curve.
Regression Residuals
These residuals are used to compute various point estimate metrics that summarize model performance on a given dataset. Common examples include:
Mean Absolute Error (MAE):
\[\text{MAE} = \frac{1}{n} \sum_{i=1}^n \left| y_i - \hat{y}_i \right|\]Mean Squared Error (MSE):
\[\text{MSE} = \frac{1}{n} \sum_{i=1}^n \left( y_i - \hat{y}_i \right)^2\]Root Mean Squared Error (RMSE):
\[\text{RMSE} = \sqrt{\text{MSE}}\]
These are considered point estimates because they provide single-value summaries of the model’s residual error without incorporating uncertainty or sampling variability. To assess the stability or confidence of these estimates, techniques such as bootstrapping can be used to generate distributions over repeated samples.
Chi-Square Tests and Cochran’s Rule
The chi-square test of independence relies on a large-sample approximation. Its sampling distribution approaches the theoretical chi-square distribution only when expected cell counts are sufficiently large. When expected counts are small, the approximation breaks down and p-values become unreliable.
Chi-Square Statistic
For a contingency table with observed counts \(O_{ij}\) and expected counts \(E_{ij}\), the chi-square statistic is:
The expected count under the null hypothesis of independence is computed from the row and column marginals:
where \(R_i\) is the total of row \(i\), \(C_j\) is the total of column \(j\), and \(N\) is the grand total.
Cochran’s Rule
Cochran (1954) provides a practical validity criterion: if more than 20% of expected cell counts fall below 5, the chi-square approximation should not be trusted. For a contingency table with \(K \times J\) cells, the rule is violated when:
When this happens, alternative tests are recommended:
For 2 x 2 tables: Fisher’s exact test
For larger tables: Fisher-Freeman-Halton exact test, or a chi-square test with a Monte Carlo simulated p-value
Worked Example: Sparse K x 2 Table
Consider a K x 2 contingency table for the Recall metric across three groups, populated with small counts:
Row totals: \(R = (3, 2, 1)\). Column totals: \(C = (4, 2)\). Grand total: \(N = 6\).
Compute the expected count for each cell:
All six expected cells fall below 5, so the violation fraction is:
Cochran’s rule is violated. The chi-square approximation is unreliable on this table, and a more appropriate test should be substituted.
Note
In EquiBoots, this check is built into _chi_square_test. When the
rule is violated on a 2 x 2 table, the implementation transparently swaps
in Fisher’s exact test. On larger K x 2 tables, a warning is emitted
recommending Fisher’s exact as a follow-up.
Reference
Kim HY (2017). Statistical notes for clinical researchers: Chi-squared test and Fisher’s exact test. Restorative Dentistry & Endodontics, 42(2), 152-155. https://pmc.ncbi.nlm.nih.gov/articles/PMC5426219/